
热门开源 AI 图像分割模型解析:技术前沿与应用实践
图像分割作为计算机视觉领域的核心技术之一,近年来在开源社区的推动下取得了显著进展。本文将深入解析几款热门的开源 AI 图像分割模型,探讨其技术特点、应用场景以及未来发展趋势,帮助读者更好地理解这一领域的最新动态。
1. 图像分割的基本概念与挑战

图像分割是指将图像中的像素划分为多个区域或对象的过程。与目标检测不同,图像分割要求对每个像素进行分类,从而实现更精细的物体边界识别。这一技术在医学影像分析、自动驾驶、卫星图像处理等领域具有广泛的应用。
然而,图像分割也面临诸多挑战,例如复杂背景下的目标识别、多尺度物体的分割精度、以及实时性要求等。开源社区通过不断优化模型架构和训练策略,为解决这些问题提供了丰富的工具和资源。
2. 热门开源图像分割模型解析
2.1 U-Net:医学影像分割的经典之选
U-Net 是图像分割领域的里程碑式模型,由德国弗莱堡大学于 2015 年提出。其独特的 U 形结构结合了编码器和解码器,能够高效地提取特征并重建高分辨率分割结果。U-Net 在医学影像分割中表现尤为突出,例如细胞分割、肿瘤检测等任务。
开源社区对 U-Net 进行了多次改进,例如加入注意力机制、多尺度特征融合等,进一步提升了其性能。此外,U-Net 的轻量化版本也被广泛应用于移动设备和嵌入式系统中。
2.2 DeepLab:语义分割的标杆
DeepLab 系列模型由谷歌团队开发,是语义分割领域的代表性工作。其核心创新在于引入了空洞卷积(Atrous Convolution)和条件随机场(CRF),能够在保持高分辨率的同时捕获多尺度上下文信息。
DeepLabV3+ 是该系列的最新版本,通过改进的解码器结构和更高效的训练策略,在多个公开数据集上取得了领先的成绩。DeepLab 广泛应用于自动驾驶、视频监控等场景,特别是在复杂环境下的语义理解方面表现优异。
2.3 Mask R-CNN:实例分割的集大成者
Mask R-CNN 是 Facebook AI 研究院于 2017 年提出的模型,结合了目标检测和图像分割的优势,能够同时输出物体的边界框和像素级掩码。其核心创新在于引入了 ROIAlign 层,解决了特征图与原始图像之间的不对齐问题。
Mask R-CNN 在实例分割任务中表现出色,例如人体姿态估计、商品识别等。开源社区对其进行了大量优化,例如加入多任务学习、自监督训练等,进一步提升了其泛化能力和效率。
3. 开源模型的未来发展趋势
随着深度学习技术的不断进步,开源图像分割模型也在朝着更高效、更智能的方向发展。以下是几个值得关注的趋势:
- 轻量化与实时性:针对移动设备和边缘计算的需求,轻量化模型将成为研究热点。例如,MobileNetV3 与 DeepLab 的结合已经在实时分割任务中取得了显著进展。
- 多模态融合:结合图像、文本、点云等多模态数据的分割模型,将进一步提升复杂场景下的分割精度。
- 自监督与无监督学习:减少对标注数据的依赖,通过自监督或无监督学习提升模型的泛化能力,是未来研究的重要方向。
- 可解释性与鲁棒性:提高模型的可解释性和对噪声、对抗样本的鲁棒性,将有助于推动图像分割技术在医疗、金融等高风险领域的应用。
4. 总结
开源 AI 图像分割模型为计算机视觉领域的发展提供了强大的支持。从 U-Net 到 DeepLab,再到 Mask R-CNN,这些模型在技术上的不断创新,推动了图像分割技术在实际应用中的广泛落地。未来,随着轻量化、多模态融合等技术的进一步发展,图像分割将在更多领域发挥重要作用。无论是开发者还是研究者,都可以通过开源社区获取丰富的资源,共同推动这一领域的进步。
希望本文的解析能够帮助读者更好地理解热门开源图像分割模型的技术特点与应用场景,并为相关领域的实践提供参考。
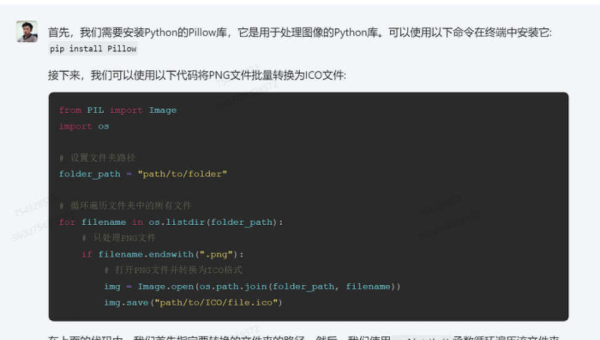

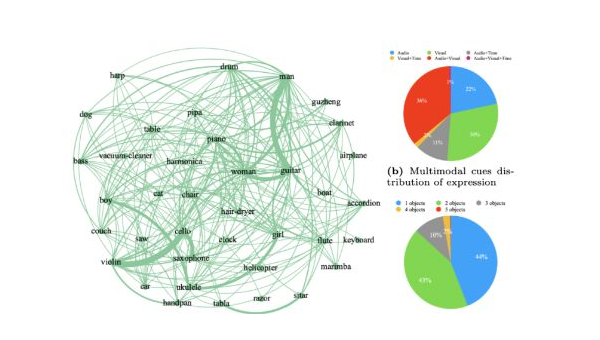





暂无评论内容